Managing Storage on Substrate Nodes: A Duniter Case Study
Introduction
The storage demands of a running Substrate node can be expensive as the network ages. Observations from the Polkadot network indicate that an archive node requires approximately 2,765 GiB of storage after 4.71 years of operation (stakeworld.io, Polkadot wiki). While the Polkadot network targets high-end users for validators with a high staking price and performant machines ensuring quality over quantity, some networks will target modest users with consumer-grade hardware, the validators' quality being accessed differently than by stacked token and hardware investment.
In this short post, I will first describe the different pruning profiles of a Substrate node, and then we will see a small analysis of a Duniter node. As the Duniter network is a proof-of-stake network with no stacking and no transaction fees, the validators are not incentivized by monetary gain but run the network by pure altruism; therefore, aiming for a low-footprint node is a primary concern.
Substrate pruning
A Substrate node offers several pruning mode capabilities at the node startup. There are two types of pruning: state pruning, where the block state (i.e., storage) is removed from the database, and block pruning, where the block body (including justifications) is removed.
Three modes are available for these prunings:
- Archive: keeps all the data of all blocks.
- Archive Canonical: keeps the data of all finalized blocks.
- n: keeps the data of the n latest blocks.
Substrate has two node types: mirror node and validator. Historically, validator nodes that contributed to the network by finalizing blocks were forced to run in archive mode, but this is not the case anymore. Hence, the analysis below is relevant for either node type.
In the next section, we will focus on the evolution of the archive node's database size over time; the pruned node database will also slowly grow but at a very moderate rate, which should not be a problem.
Method
To provide an accurate estimate of storage requirements, I monitored the storage of a full archive node:
target/release/duniter --chain=gdev --blocks-pruning=archive --state-pruning=archive
I recorded the imported block number and the node's storage usage every 30 seconds, maintaining this process consistently over several weeks.
Results
Figure 1 illustrates the relationship between the number of imported blocks and the node's corresponding disk space usage. The data reveals a clear non-linear growth in storage over the observation period. On shorter time scales, this growth manifests as discrete steps, highlighting periods of sudden increases in storage consumption.
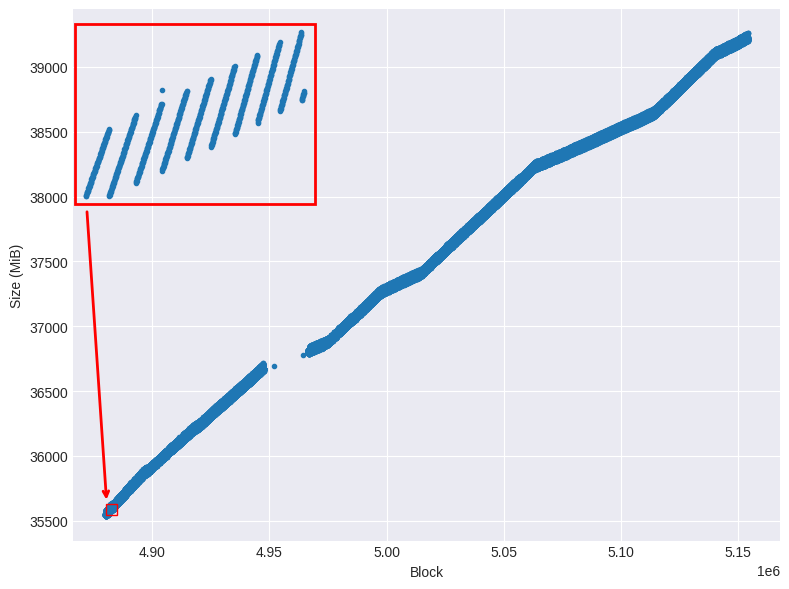
Figure 2 illustrates the distribution of the duration of these discrete steps in block numbers. The step durations are highly variable, with a noticeable predominance around 100 blocks (equivalent to 10 minutes).
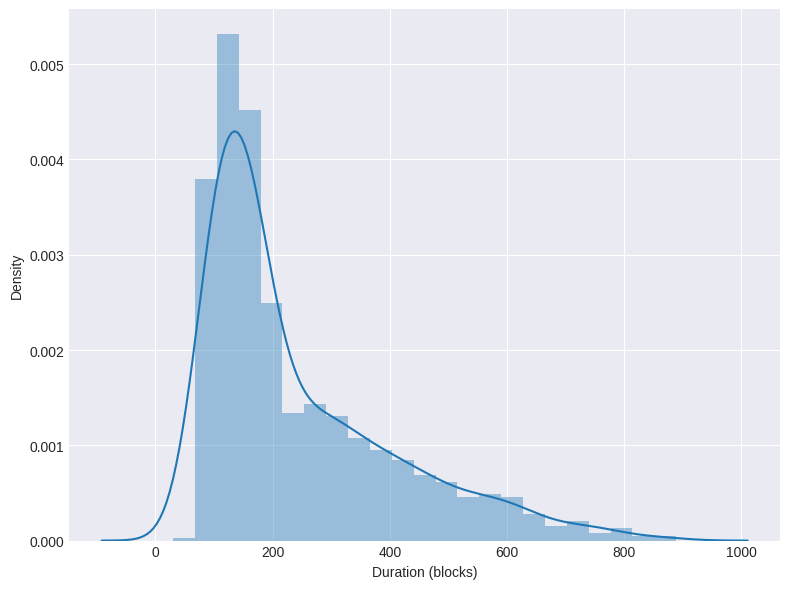
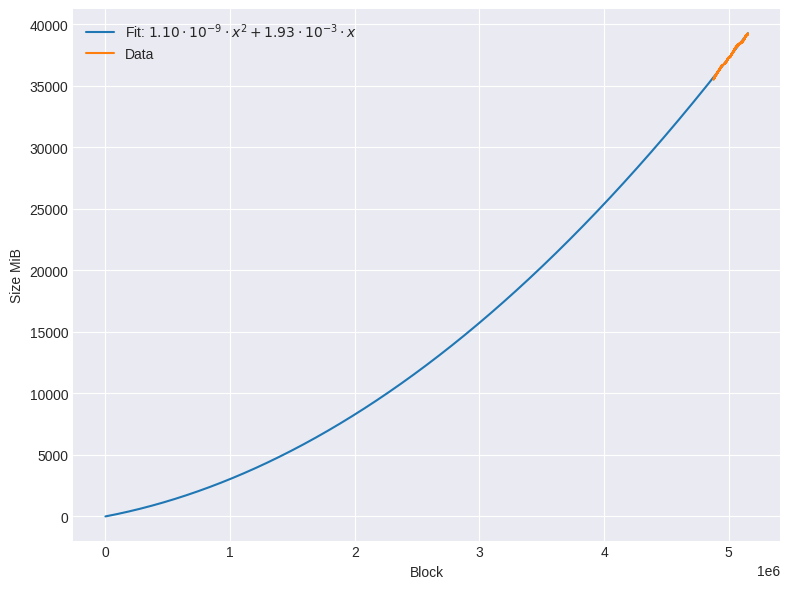
Figure 3 presents the evolution of the node's disk space usage, displaying both the recorded data and the fitted curve. The fitting assumes that the disk space at block 0 is approximately zero. To model the growth behavior, the data was fitted using the simplest continuous function that provided an adequate representation: a second-degree polynomial without a constant term. This function highlights the accelerating nature of storage requirements as the blockchain progresses.
Prediction
I have not yet conducted a detailed investigation into the stepwise increase in storage usage, a behavior also observed in other chain nodes utilizing ParityDB. While this phenomenon does not directly influence the overall growth in storage size, its underlying cause remains unclear. It is likely attributable to either deferred file deletion at the database/system level or quasi-periodic compression of intermediate data structures at the node level. Recording data from a node operating with RocksDB should provide some insights to clarify the source of this behavior.
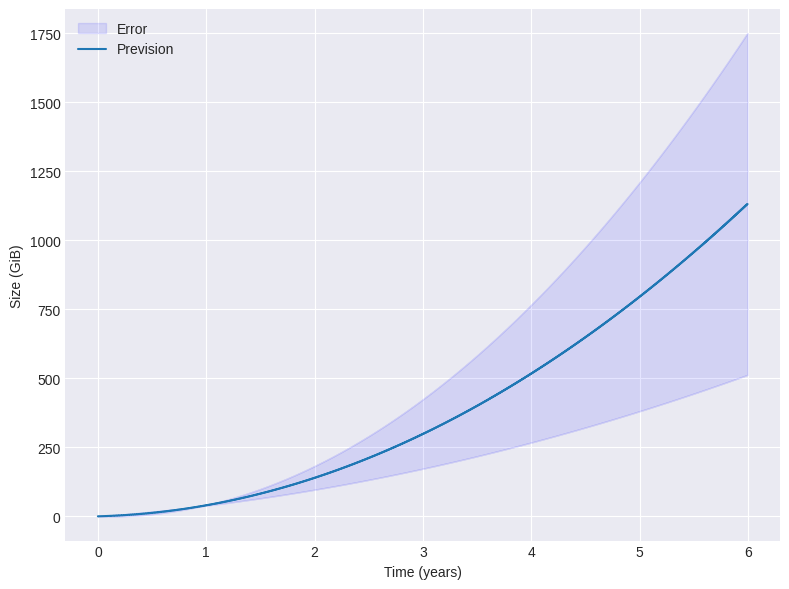
Based on the observed results, disk space usage follows a non-linear trend. The limited data collected can be accurately fitted using a second-degree polynomial. Figure 4 presents the projected disk space usage based on this polynomial fit alongside the propagated error margins derived from the fit's covariance matrix. This preliminary forecast of storage requirements highlights the uncertainty inherent to the limited current dataset.
Observations from the Polkadot network indicate that an archive node requires approximately 2,765 GiB of storage after 4.71 years of operation (stakeworld.io, Polkadot wiki). In contrast, the Duniter network remains largely inactive, with storage growth primarily driven by the operations necessary to finalize empty blocks and maintain basic network functions.
Given these conditions, our prediction of 500 ± 250 GiB of storage after 4 years—based on limited data—appears plausible compared to heavily utilized networks like Polkadot. This estimate offers a rough benchmark of future storage demands, especially when viewed alongside long-running networks such as Polkadot and Kusama, where higher activity levels contribute significantly to storage growth.
Conclusion
The currently available data result in a model with moderate predictive power for up to 2 years and low predictive power beyond that. However, it offers a reasonable estimate, especially when combined with the observed Polkadot node storage requirements trends. These observations indicate that over the next 3 to 4 years, storage demands are unlikely to exceed 1 TiB. This prediction aligns with the targeted reference machine's capabilities and fits within the current SSD size and pricing trends for modest hardware requirements that Duniter aims to maintain.
Monitoring disk space usage on active nodes will be crucial to refine these predictions, particularly as network activity increases. A rise in transaction volume, especially with on-chain storage of transaction comments, could have a notable impact on future storage needs. Regularly updating the model can ensure more accurate forecasting as the network and its dynamics evolve.
Several measures can be implemented for blockchains like Duniter that target regular users with moderate machines (the reference machine for the weights computation is a Raspberry PI).
The first is drastic but one of the most effective, consisting of allonging the block duration. Even for a network without transactions, the database is growing non-linearly, and allonging block production, while resulting in a slower network, will decrease the storage growth significantly.
Another solution is to remember that archive nodes are very specialized nodes with only one purpose: to provide blockchain analyzers with all the data from the start of the node. For example, Duniter uses a subsquid indexer to quickly aggregate and serve historical or current data to apps without relying on direct node querying. The number of archive nodes needed for a healthy network is low. Therefore, monetary incentives for these users can be considered to reward the hardware investment.